pPLUS® AAV-Helper
pPLUS® AAV-Helper is a novel plasmid helper designed for AAV production. This plasmid has been optimized for triple transfection of HEK293 cells in s...
![]()
![]()
Life Sciences
Tailor-made DNA plasmid that really fits your needs
Innovative assembly Technology (e-Zyvec®)
Seamless DNA assembly to produce very complex plasmids
De-risking plasmid engineering
Access to dedicated plasmid experts and online software to support your project
Reliable plasmid sequence
Full-length plasmid sequencing included
Time-Saving
Ready-to-use discovery grade plasmids from 3 weeks from ordering
At Polyplus, we have developed a unique and innovative DNA assembly technology(e-Zyvec®) to offer tailor-made plasmid engineering and production services for plasmids, from Discovery grade to GMP grade manufacturing. Our e-Zyvec® assembly technology is based on the use of linear DNA bricks, designed and build to produce the final plasmid construct. Plasmid design is therefore flexible and accurate, allowing the generation of any plasmid from the easiest to the most sophisticated one.
Our Plasmid Experts are here to identify your needs from the start of your project, you will receive ready-to-use plasmids that will fit with your project expectation and full-length validated by Next Generation Sequencing as QC. Using our online plasmid platform, you can design your plasmid and share it with your team & our experts to be reviewed!
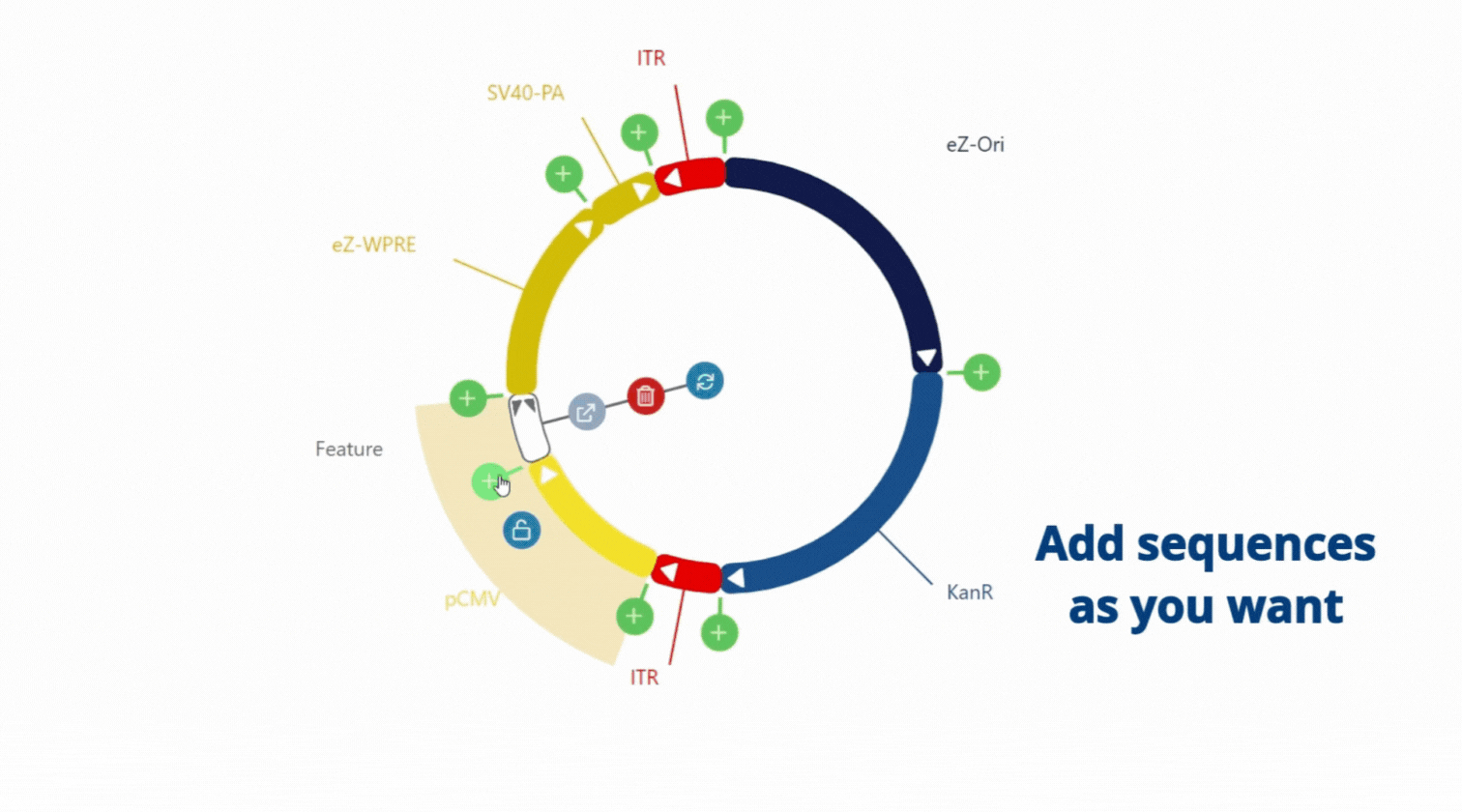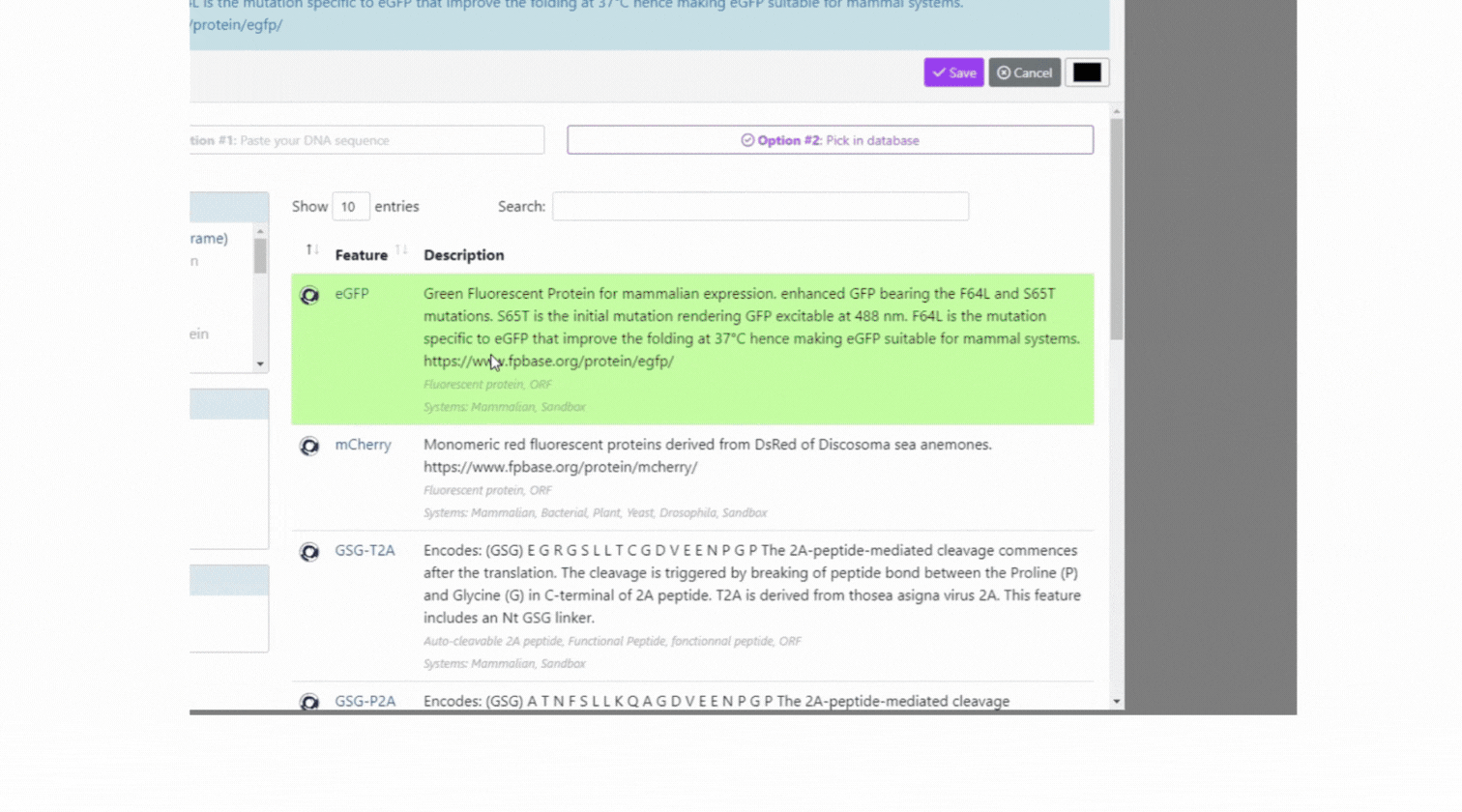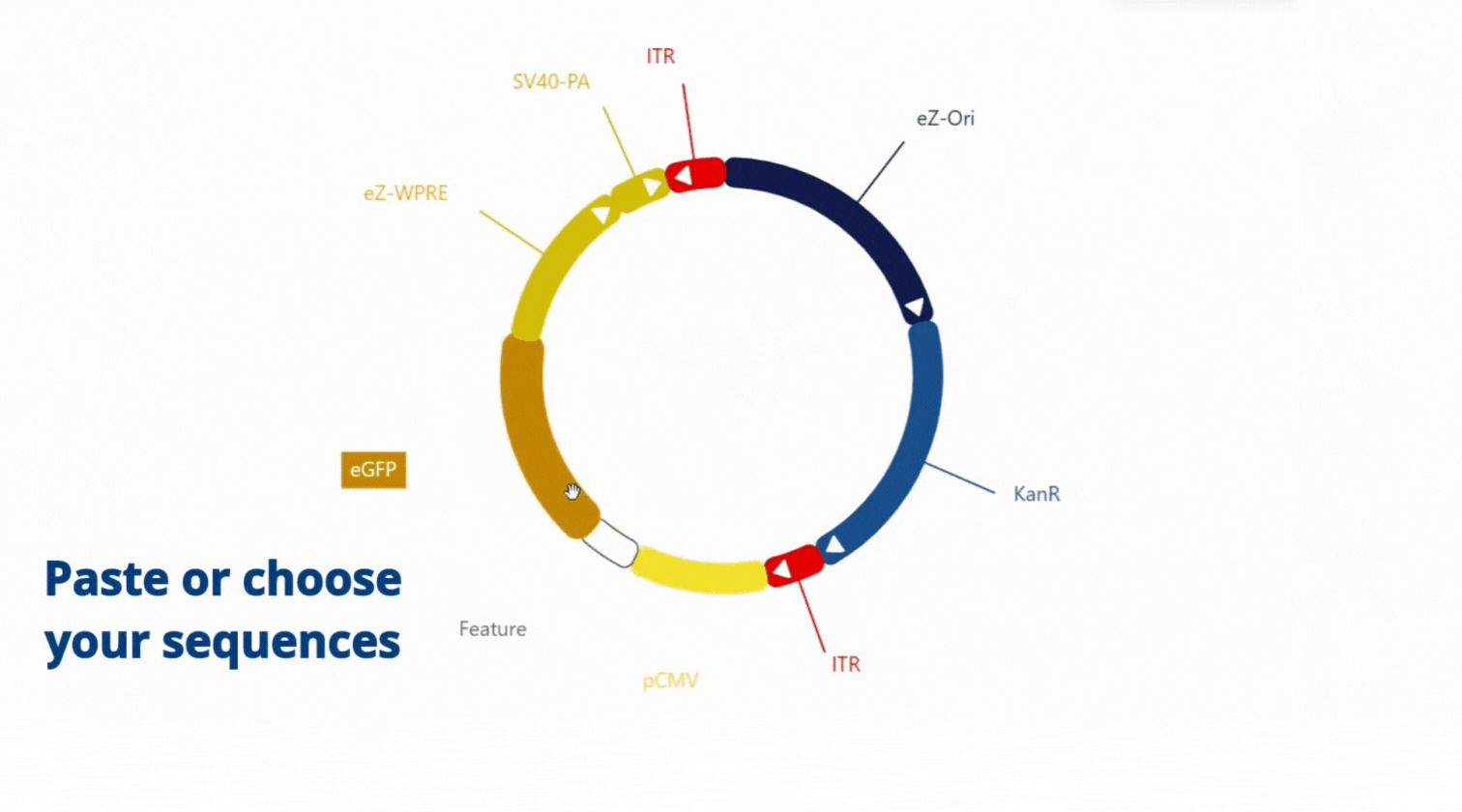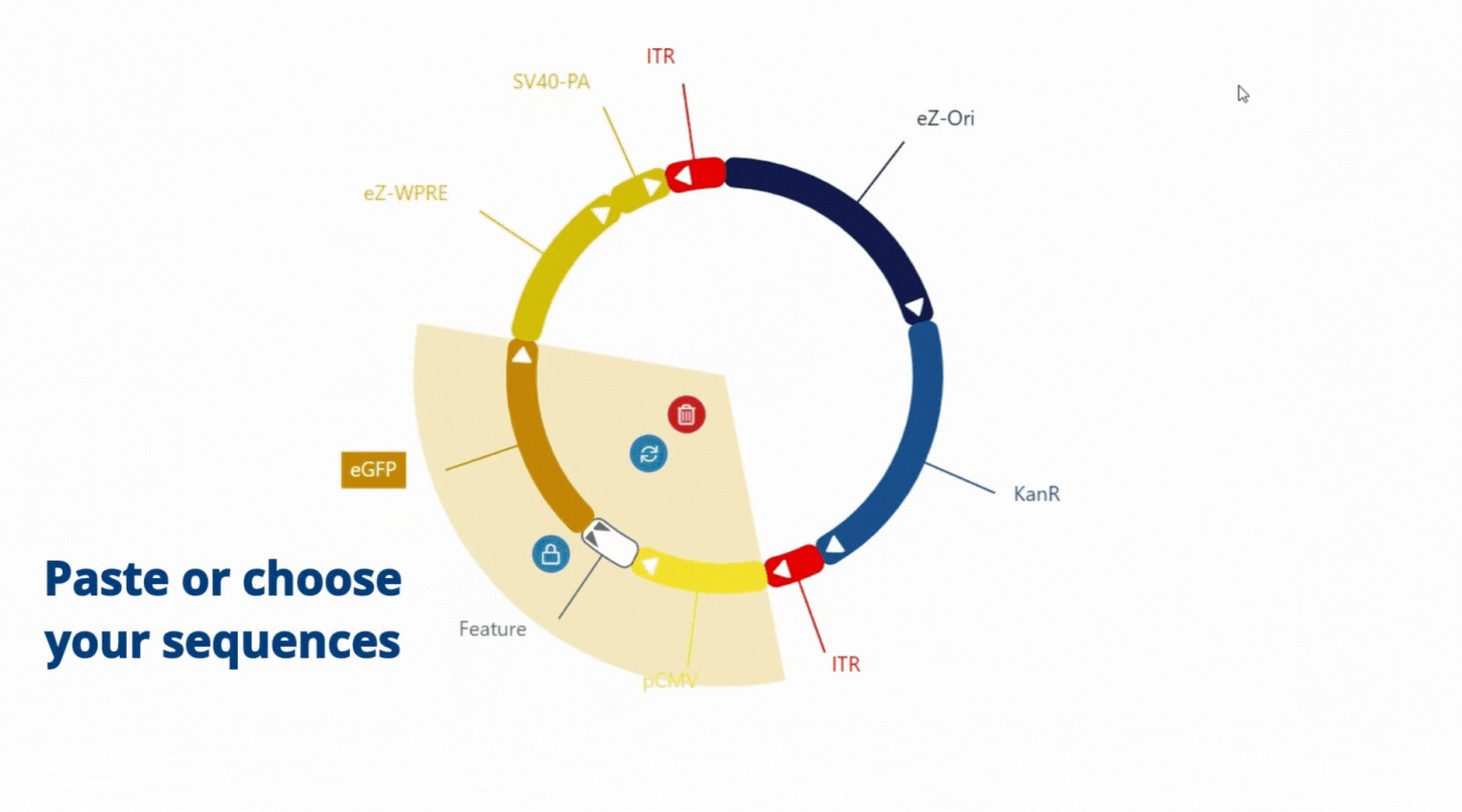
Move, choose and paste sequence as you want, everything is flexible .
At Polyplus, we offer a complete modular approach to plasmid design, which means that we can accommodate a wide range of requests. Whether you need a plasmid with repeated sequences, a high or low GC content, a very long sequence of interest, or multiple transgenes, we can assemble any plasmid to meet your specific needs. Our team of experts has years of experience in plasmid engineering, and thanks to e-Zyvec® technology we guarantee that each plasmid we design is accurate. If the kind of plasmid you need does not exist yet, don’t worry! We will work closely with you to design and build a plasmid that meets your exact specifications.
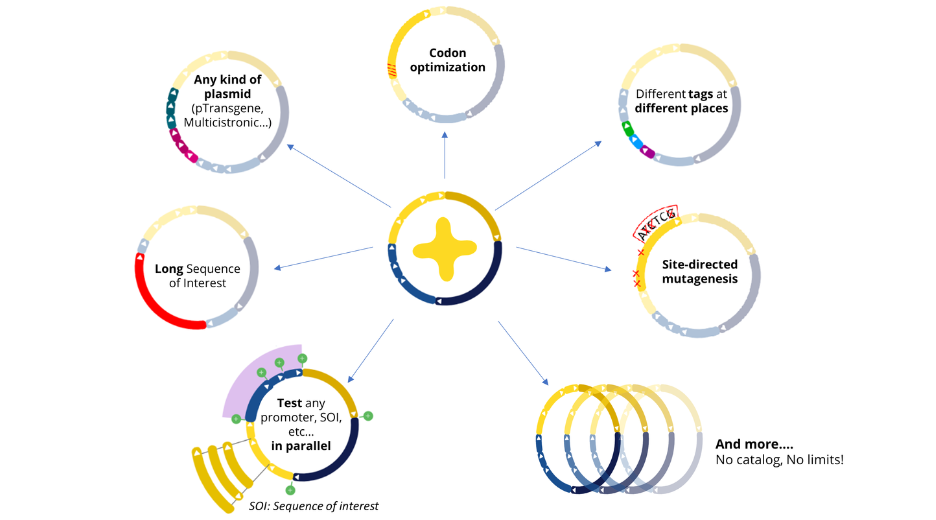
With our easy-to-use platform and our team of experts, designing plasmids has never been so easy. After designing your plasmid on our online platform, you will be in touch with our Plasmids scientist to review your plasmids, get advice and suggestions! Once you validate the design, our Experts and our proprietary software will engineer your plasmid to get highest chance to succeed getting your plasmids (99% success rate)!
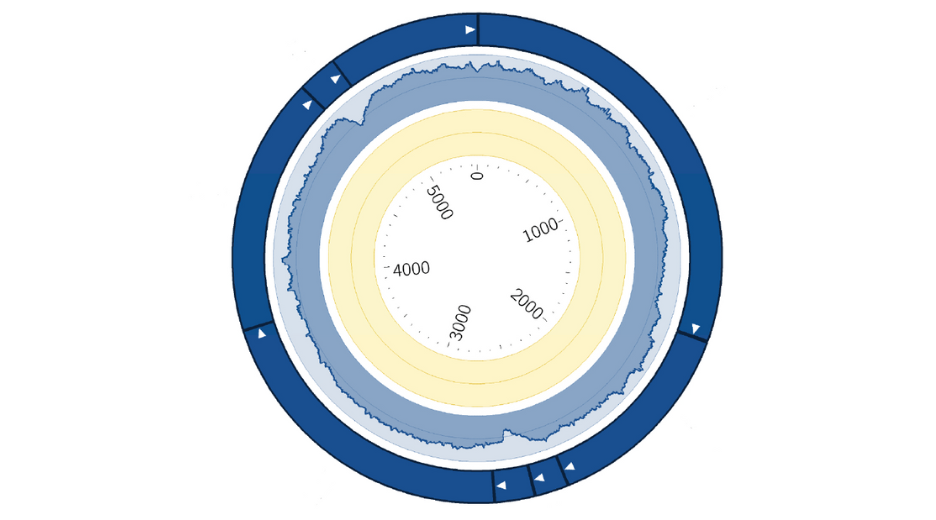
Downstream applications can be impacted by unexpected mutations and incorrect sequence information, which can impede progress and require troubleshooting that can slow down research. To avoid these issues, our service uses Next Generation Sequencing to provide high-quality, high-throughput complete plasmid sequencing and de novo assembly. Our comprehensive quality controls are included in our service, and we provide personalized reports to ensure that you have all the information you need to move forward with confidence.
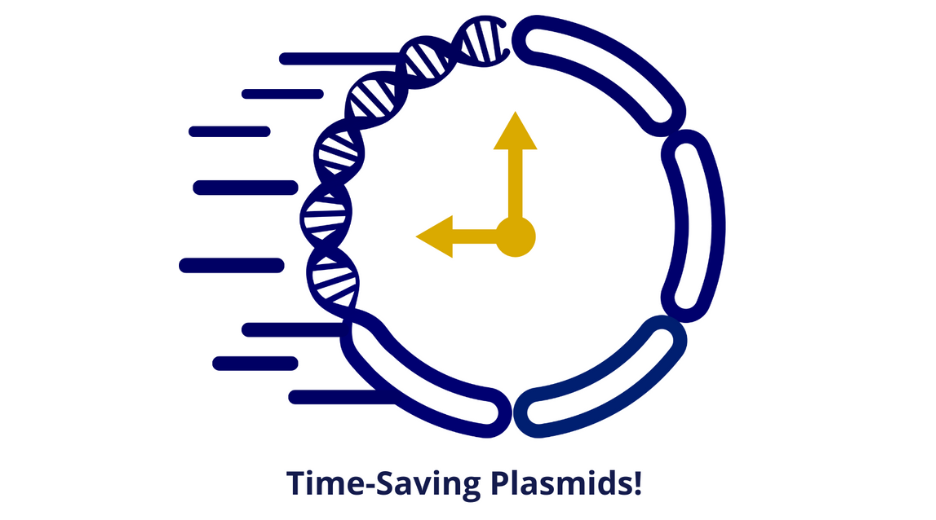
At Polyplus, we understand that time is of the essence when it comes to plasmid engineering. That’s why we offer a range of services designed to save you time and streamline the plasmid design process in two format Premium (3-4 weeks) and standard (from 5 weeks). With our online plasmid drawing tool, you can design and customize your plasmids quickly and easily, without the need for extensive technical knowledge. Additionally, our team of experts is available to provide advice and support throughout the plasmid design process, ensuring that your project stays on track and is completed in a timely manner. By utilizing our services, you can save time and resources, allowing you to focus on the important work of advancing your research.).
pPLUS® AAV-Helper is a novel plasmid helper designed for AAV production. This plasmid has been optimized for triple transfection of HEK293 cells in s...
jetOPTIMUS® is an innovative cationic nanotechnology developed to improve DNA transfection efficiency in hard-to-transfect cells.
Obtain accurate and reliable full length plasmid sequencing with our Next Generation Sequencing service.

Polyplus offers a comprehensive range of plasmid manufacturing services from DNA plasmid design to plasmid DNA manufacturing and analytical testing.

Polyplus® free of charge viral vector DOE service is the combination of our expertise in the field of nucleic acid delivery and in DoE methodology.

These FAQs are organized by application to guide you to find the best answer possible.

You have access to all the documents related to the transfection reagent.

Search for publications in our Transfection Database with Polyplus transfection reagents

This lexicon will help you to understand the different terms related to Polyplus-transfection®.